Quick Template: Serial Mediation with Latent Variables
2026-03-10
Source:vignettes/articles/template_n_from_power_mediation_lav_serial.Rmd
template_n_from_power_mediation_lav_serial.RmdIntroduction
This and other “Quick Template” articles are examples of R code to determine the range of sample sizes for a target level of power in typical models using power4mome. Users can quickly adapt them for their scenarios. A summary of the code examples can be found in the section Code Template at the end of this document.
Prerequisite
Basic knowledge about fitting models by lavaan and
power4mome is required.
This file is not intended to be an introduction on how to use
functions in power4mome. For details on how to use
power4test(), refer to the Get-Started
article. Please also refer to the help page of
n_region_from_power(), and the article
on n_from_power(), which is called twice by
n_region_from_power() to find the regions described
below.
Functions Used in This Template
-
- Set up the model and the population values, generate the data, and generate the Monte Carlo simulated estimates for Monte Carlo confidence interval.
-
- Find the regions of sample sizes based on the target power.
-
- Test the indirect effect using Monte Carlo or bootstrap confidence
intervals. Used by
power4test().
- Test the indirect effect using Monte Carlo or bootstrap confidence
intervals. Used by
Common Flow
The following chart summarizes the steps covered below.
Common Workflow
In practice, steps can be repeated, and population values changed, until the desired goal is achieved (e.g., the region of sample sizes with power close to the target power is found).
Set Up The Model and Test
Load the package first:
Estimate the power for a sample size.
The code for the model:
# ====== Model: Form ======
# Omit any paths hypothesized to be zero
model <-
"
m1 ~ x
m2 ~ m1 + x
m3 ~ m2 + m1 + x
y ~ m3 + m2 + m1 + x
"
# ====== Model: Population Values ======
# l: large (.50 by default)
# m: medium (.30 by default)
# s: small (.10 by default)
# n: nil (.00 by default)
# -l, -m, and -s denote negative values
# Omitted paths are zero by default
# Can also set to a number directly
# Set each path to the hypothesized magnitude
model_es <-
"
m1 ~ x: l
m2 ~ m1: l
m3 ~ m2: l
y ~ m3: m
y ~ x: s
"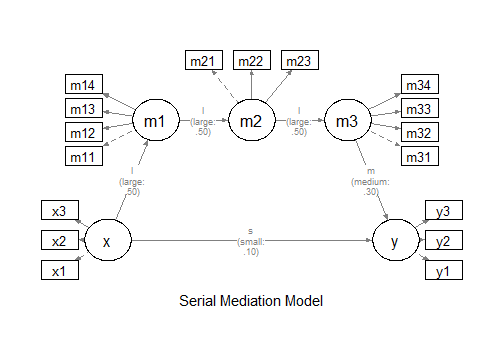
The Model
Refer to this article
on how to set number_of_indicators and
reliability when calling power4test().
# ====== Test the Model Specification ======
out <- power4test(nrep = 2,
model = model,
pop_es = model_es,
n = 50000,
number_of_indicators = c(x = 3,
m1 = 4,
m2 = 3,
m3 = 4,
y = 3),
reliability = c(x = .80,
m1 = .70,
m2 = .70,
m3 = .70,
y = .80),
iseed = 1234)
# ====== Check the Data Generated ======
print(out,
data_long = TRUE)
# ====== Estimate the Power ======
# For n = 200,
# when testing the indirect effect by
# Monte Carlo confidence interval
out <- power4test(nrep = 600,
model = model,
pop_es = model_es,
n = 200,
R = 1000,
number_of_indicators = c(x = 3,
m1 = 4,
m2 = 3,
m3 = 4,
y = 3),
reliability = c(x = .80,
m1 = .70,
m2 = .70,
m3 = .70,
y = .80),
ci_type = "mc",
test_fun = test_indirect_effect,
test_args = list(x = "x",
m = c("m1", "m2", "m3"),
y = "y",
mc_ci = TRUE),
iseed = 1234,
parallel = TRUE)
# ====== Compute the Rejection Rate ======
rejection_rates(out)The results:
print(out,
data_long = TRUE)
#>
#> ====================== Model Information ======================
#>
#> == Model on Factors/Variables ==
#>
#> m1 ~ x
#> m2 ~ m1 + x
#> m3 ~ m2 + m1 + x
#> y ~ m3 + m2 + m1 + x
#>
#> == Model on Variables/Indicators ==
#>
#> m1 ~ x
#> m2 ~ m1 + x
#> m3 ~ m2 + m1 + x
#> y ~ m3 + m2 + m1 + x
#>
#> m1 =~ m11 + m12 + m13 + m14
#> m2 =~ m21 + m22 + m23
#> m3 =~ m31 + m32 + m33 + m34
#> y =~ y1 + y2 + y3
#> x =~ x1 + x2 + x3
#> ====== Population Values ======
#>
#> Regressions:
#> Population
#> m1 ~
#> x 0.500
#> m2 ~
#> m1 0.500
#> x 0.000
#> m3 ~
#> m2 0.500
#> m1 0.000
#> x 0.000
#> y ~
#> m3 0.300
#> m2 0.000
#> m1 0.000
#> x 0.100
#>
#> Variances:
#> Population
#> .m1 0.750
#> .m2 0.750
#> .m3 0.750
#> .y 0.893
#> x 1.000
#>
#> (Computing indirect effects for 8 paths ...)
#>
#> == Population Conditional/Indirect Effect(s) ==
#>
#> == Indirect Effect(s) ==
#>
#> ind
#> x -> m1 -> m2 -> m3 -> y 0.037
#> x -> m1 -> m2 -> y 0.000
#> x -> m1 -> m3 -> y 0.000
#> x -> m1 -> y 0.000
#> x -> m2 -> m3 -> y 0.000
#> x -> m2 -> y 0.000
#> x -> m3 -> y 0.000
#> x -> y 0.100
#>
#> - The 'ind' column shows the indirect effect(s).
#>
#> ==== Population Reliability ====
#>
#> x m1 m2 m3 y
#> 0.8 0.7 0.7 0.7 0.8
#>
#> == Population Standardized Loadings ==
#>
#> Standardized Loadings
#> x 0.756,0.756,0.756
#> m1 0.607,0.607,0.607,0.607
#> m2 0.661,0.661,0.661
#> m3 0.607,0.607,0.607,0.607
#> y 0.756,0.756,0.756
#>
#> ======================= Data Information =======================
#>
#> Number of Replications: 600
#> Sample Sizes: 200
#>
#> ==== Descriptive Statistics ====
#>
#> vars n mean sd skew kurtosis se
#> x1 1 120000 0.00 1 0.00 -0.01 0
#> x2 2 120000 0.00 1 0.00 -0.02 0
#> x3 3 120000 0.00 1 0.01 0.00 0
#> m11 4 120000 0.00 1 0.00 0.00 0
#> m12 5 120000 0.00 1 0.00 0.00 0
#> m13 6 120000 0.00 1 -0.01 0.01 0
#> m14 7 120000 0.00 1 0.00 -0.02 0
#> m21 8 120000 0.00 1 0.00 -0.04 0
#> m22 9 120000 0.00 1 -0.01 0.00 0
#> m23 10 120000 0.01 1 0.00 0.01 0
#> m31 11 120000 0.00 1 0.00 -0.02 0
#> m32 12 120000 0.00 1 -0.01 0.00 0
#> m33 13 120000 0.01 1 0.01 0.00 0
#> m34 14 120000 0.00 1 0.02 0.01 0
#> y1 15 120000 0.00 1 0.01 0.02 0
#> y2 16 120000 0.00 1 0.00 0.02 0
#> y3 17 120000 0.00 1 0.01 0.00 0
#>
#> ==== Parameter Estimates Based on All 600 Samples Combined ====
#>
#> Total Sample Size: 120000
#>
#> ==== Standardized Estimates ====
#>
#> Variances and error variances omitted.
#>
#> Latent Variables:
#> est.std
#> m1 =~
#> m11 0.607
#> m12 0.606
#> m13 0.609
#> m14 0.608
#> m2 =~
#> m21 0.662
#> m22 0.660
#> m23 0.663
#> m3 =~
#> m31 0.607
#> m32 0.605
#> m33 0.607
#> m34 0.604
#> y =~
#> y1 0.754
#> y2 0.757
#> y3 0.757
#> x =~
#> x1 0.758
#> x2 0.755
#> x3 0.752
#>
#> Regressions:
#> est.std
#> m1 ~
#> x 0.508
#> m2 ~
#> m1 0.501
#> x -0.005
#> m3 ~
#> m2 0.499
#> m1 -0.000
#> x -0.001
#> y ~
#> m3 0.300
#> m2 -0.000
#> m1 0.001
#> x 0.097
#>
#>
#> ==================== Extra Element(s) Found ====================
#>
#> - fit
#> - mc_out
#>
#> === Element(s) of the First Dataset ===
#>
#> ============ <fit> ============
#>
#> lavaan 0.6-21 ended normally after 34 iterations
#>
#> Estimator ML
#> Optimization method NLMINB
#> Number of model parameters 44
#>
#> Number of observations 200
#>
#> Model Test User Model:
#>
#> Test statistic 108.973
#> Degrees of freedom 109
#> P-value (Chi-square) 0.483
#>
#> =========== <mc_out> ===========
#>
#>
#> == A 'mc_out' class object ==
#>
#> Number of Monte Carlo replications: 1000
#>
#>
#> ========== <test_indirect: x->m1->m2->m3->y> ==========
#>
#> Mean(s) across replication:
#> est cilo cihi sig pvalue
#> 0.040 0.001 0.102 0.628 0.082
#>
#> - The value 'sig' is the rejection rate.
#> - If the null hypothesis is false, this is the power.
#> - Number of valid replications for rejection rate: 600
#> - Proportion of valid replications for rejection rate: 1.000
rejection_rates(out)
#> [test]: test_indirect: x->m1->m2->m3->y
#> [test_label]: Test
#> est p.v reject r.cilo r.cihi
#> 1 0.040 1.000 0.628 0.589 0.666
#> Notes:
#> - p.v: The proportion of valid replications.
#> - est: The mean of the estimates in a test across replications.
#> - reject: The proportion of 'significant' replications, that is, the
#> rejection rate. If the null hypothesis is true, this is the Type I
#> error rate. If the null hypothesis is false, this is the power.
#> - r.cilo,r.cihi: The confidence interval of the rejection rate, based
#> on Wilson's (1927) method.
#> - Refer to the tests for the meanings of other columns.Find the Regions of N Based on the Target Power
Search, by simulation, the following two regions of sample sizes:
Sample sizes with estimated levels of power significantly below the target level (e.g., .80), tested by the confidence interval (95% by default).
Sample sizes with estimated levels of power significantly above the target level (e.g., .80), tested by the confidence interval (95% by default).
In practice, we rarely need high precision for these regions for sample size planning. Therefore, we only need to find the two sample sizes with the corresponding confidence bounds close enough to the target power, defined by a tolerance value. In the function below, this value is .02 by default.
It can take some time to run if the estimated power of the sample size is too different from the target power.
We can find the two regions by
n_region_from_power().
The code:
#
# ===== Reuse the output of power4test() =====
#
# Call n_region_from_power()
# - Set target power: target_power = .80 (Default, can be omitted)
# - Set the seed for the simulation: Integer. Should always be set.
# To set desired precision:
# - Set final number of R: final_R. If omitted,
# it is set to 1000 or set to R in the original object.
# - Set final number of replications: final_nrep. If omitted,
# it is set to 400 or set to nrep in the original object.
n_power_region <- n_region_from_power(out,
seed = 1357)
# ===== Basic Results =====
n_power_region
# ===== Plot the (Crude) Power Curve and the Regions =====
plot(n_power_region)The results:
# ===== Basic Results =====
n_power_region
#> Call:
#> n_region_from_power(object = out, seed = 1357)
#>
#> Setting
#> Predictor(x) Sample Size
#> Goal: Power significantly below or above the target
#> algorithm: bisection
#> Level of confidence: 95.00%
#> Target Power: 0.800
#>
#> Solution:
#>
#> Approximate region of sample sizes with power:
#> - not significantly different from 0.800: 228 to 289
#> - significantly lower than 0.800: 228
#> - significantly higher than 0.800: 289
#>
#> Confidence intervals of the estimated power:
#> - for the lower bound (228): [0.712, 0.781]
#> - for the upper bound (289): [0.812, 0.870]
#>
#> Call `summary()` for detailed results.
# ===== Plot the (Crude) Power Curve and the Regions =====
plot(n_power_region)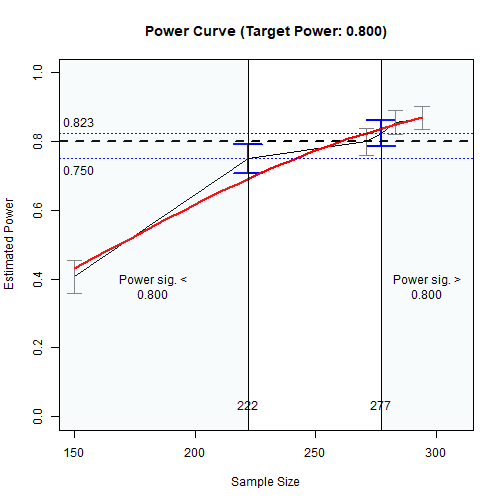
Power Curve
As shown above, approximately:
sample sizes lower than 228 have power significantly lower than .80, and
sample sizes higher than 289 have power significantly higher than .80.
In other words, sample sizes between 228 and 289 have power not significantly different from .80.
If necessary, detailed results can be printed by
summary():
# ===== Detailed Results =====
summary(n_power_region)
#>
#> ======<< Summary for the Lower Region >>======
#>
#>
#> ====== x_from_power Results ======
#>
#> Call:
#> x_from_power(object = out, x = "n", what = "ub", goal = "close_enough",
#> final_nrep = 600, final_R = 1000, seed = 1357)
#>
#> Predictor (x): Sample Size
#>
#> - Target Power: 0.800
#> - Goal: Find 'x' with estimated upper confidence bound close enough to
#> the target power.
#>
#> === Major Results ===
#>
#> - Final Value (Sample Size): 228
#>
#> - Final Estimated Power: 0.748
#> - Confidence Interval: [0.712; 0.781]
#> - Level of confidence: 95.0%
#> - Based on 600 replications.
#>
#> === Technical Information ===
#>
#> - Algorithm: bisection
#> - Tolerance for 'close enough': Within 0.02000 of 0.800
#> - The range of values explored: 200 to 255
#> - Time spent in the search: 1.392 mins
#> - The final crude model for the power-predictor relation:
#>
#> Model Type: Logistic Regression
#>
#> Call:
#> power_curve(object = by_x_1, formula = power_model, start = power_curve_start,
#> lower_bound = lower_bound, upper_bound = upper_bound, nls_args = nls_args,
#> nls_control = nls_control, verbose = progress)
#>
#> Predictor: n (Sample Size)
#>
#> Model:
#>
#> Call: stats::glm(formula = reject ~ x, family = "binomial", data = reject1)
#>
#> Coefficients:
#> (Intercept) x
#> -2.75160 0.01653
#>
#> Degrees of Freedom: 1799 Total (i.e. Null); 1798 Residual
#> Null Deviance: 2110
#> Residual Deviance: 2062 AIC: 2066
#>
#> - Detailed Results:
#>
#> [test]: test_indirect: x->m1->m2->m3->y
#> [test_label]: Test
#> n est p.v reject r.cilo r.cihi
#> 1 200 0.040 1.000 0.628 0.589 0.666
#> 2 228 0.040 1.000 0.748 0.712 0.781
#> 3 255 0.040 1.000 0.805 0.771 0.835
#> Notes:
#> - n: The sample size in a trial.
#> - p.v: The proportion of valid replications.
#> - est: The mean of the estimates in a test across replications.
#> - reject: The proportion of 'significant' replications, that is, the
#> rejection rate. If the null hypothesis is true, this is the Type I
#> error rate. If the null hypothesis is false, this is the power.
#> - r.cilo,r.cihi: The confidence interval of the rejection rate, based
#> on Wilson's (1927) method.
#> - Refer to the tests for the meanings of other columns.
#>
#>
#>
#> ======<< Summary for the Upper Region >>======
#>
#>
#> ====== x_from_power Results ======
#>
#> Call:
#> x_from_power(object = out, seed = 1357, final_nrep = 600, final_R = 1000,
#> x = "n", what = "lb", goal = "close_enough")
#>
#> Predictor (x): Sample Size
#>
#> - Target Power: 0.800
#> - Goal: Find 'x' with estimated lower confidence bound close enough to
#> the target power.
#>
#> === Major Results ===
#>
#> - Final Value (Sample Size): 289
#>
#> - Final Estimated Power: 0.843
#> - Confidence Interval: [0.812; 0.870]
#> - Level of confidence: 95.0%
#> - Based on 600 replications.
#>
#> === Technical Information ===
#>
#> - Algorithm: bisection
#> - Tolerance for 'close enough': Within 0.02000 of 0.800
#> - The range of values explored: 137 to 534
#> - Time spent in the search: 4.456 mins
#> - The final crude model for the power-predictor relation:
#>
#> Model Type: Nonlinear Regression Model
#>
#> Call:
#> power_curve(object = by_x_1, formula = power_model, start = power_curve_start,
#> lower_bound = lower_bound, upper_bound = upper_bound, nls_args = nls_args,
#> nls_control = nls_control, verbose = progress)
#>
#> Predictor: n (Sample Size)
#>
#> Model:
#> Nonlinear regression model
#> model: reject ~ 1 - I(exp((a - x)/b))
#> data: "(Omitted)"
#> a b
#> 94.6 103.3
#> residual sum-of-squares: 0.8086
#>
#> Algorithm "port", convergence message: both X-convergence and relative convergence (5)
#>
#> - Detailed Results:
#>
#> [test]: test_indirect: x->m1->m2->m3->y
#> [test_label]: Test
#> n est p.v reject r.cilo r.cihi
#> 1 137 0.041 1.000 0.337 0.300 0.375
#> 2 200 0.040 1.000 0.628 0.589 0.666
#> 3 228 0.040 1.000 0.748 0.712 0.781
#> 4 255 0.040 1.000 0.805 0.771 0.835
#> 5 260 0.039 1.000 0.785 0.750 0.816
#> 6 265 0.039 1.000 0.795 0.761 0.825
#> 7 289 0.039 1.000 0.843 0.812 0.870
#> 8 338 0.038 1.000 0.908 0.883 0.929
#> 9 534 0.038 1.000 0.980 0.965 0.989
#> Notes:
#> - n: The sample size in a trial.
#> - p.v: The proportion of valid replications.
#> - est: The mean of the estimates in a test across replications.
#> - reject: The proportion of 'significant' replications, that is, the
#> rejection rate. If the null hypothesis is true, this is the Type I
#> error rate. If the null hypothesis is false, this is the power.
#> - r.cilo,r.cihi: The confidence interval of the rejection rate, based
#> on Wilson's (1927) method.
#> - Refer to the tests for the meanings of other columns.Code Template
This is the code used above:
library(power4mome)
# ====== Model and Effect Size (Population Values) ======
model <-
"
m1 ~ x
m2 ~ m1 + x
m3 ~ m2 + m1 + x
y ~ m3 + m2 + m1 + x
"
model_es <-
"
m1 ~ x: l
m2 ~ m1: l
m3 ~ m2: l
y ~ m3: m
y ~ x: s
"
# Test the Model Specification
out <- power4test(nrep = 2,
model = model,
pop_es = model_es,
n = 50000,
number_of_indicators = c(x = 3,
m1 = 4,
m2 = 3,
m3 = 4,
y = 3),
reliability = c(x = .80,
m1 = .70,
m2 = .70,
m3 = .70,
y = .80),
iseed = 1234)
# Check the Data Generated
print(out,
data_long = TRUE)
# ====== Try One N and Estimate the Power ======
# For n = 200,
# when testing the indirect effect by
# Monte Carlo confidence interval
out <- power4test(nrep = 600,
model = model,
pop_es = model_es,
n = 200,
R = 1000,
number_of_indicators = c(x = 3,
m1 = 4,
m2 = 3,
m3 = 4,
y = 3),
reliability = c(x = .80,
m1 = .70,
m2 = .70,
m3 = .70,
y = .80),
ci_type = "mc",
test_fun = test_indirect_effect,
test_args = list(x = "x",
m = c("m1", "m2", "m3"),
y = "y",
mc_ci = TRUE),
iseed = 1234,
parallel = TRUE)
rejection_rates(out)
# ====== Regions of Ns ======
# Call n_region_from_power()
# - Set target power: target_power = .80 (Default, can be omitted)
# - Set the seed for the simulation: Integer. Should always be set.
# To set desired precision:
# - Set final number of R: final_R. If omitted,
# it is set to 1000 or set to R in the original object.
# - Set final number of replications: final_nrep. If omitted,
# it is set to 400 or set to nrep in the original object.
n_power_region <- n_region_from_power(out,
seed = 1357)
n_power_region
plot(n_power_region)
summary(n_power_region)Final Remarks
For a moderate to small nrep, the results may be
sensitive to the seed. It is advised to do a final check of
the sample size to be used using power4test() and an
nrep of 1000 or 2000.
For other options of power4test() and
n_region_from_power(), please refer to their help pages, as
well as the Get-Started article and this
article for
n_from_power(), which is the function to find one of the
regions, called twice by n_region_from_power().